
Using MySQL Workbench
Workbench is the recommended starting point if you want to explore the database interactively: browse schemas, sort and filter result grids, build queries with autocomplete, inspect indexes, and see relationships diagrammatically. Most researchers find it the fastest way to learn what’s in the database and to draft the SQL they’ll later move into an R or Python script.
Use Workbench for exploration; use R or Python for reproducible analysis (where your query should live in a script so it can be re-run, version-controlled, and shared).
Download MySQL Workbench from the Oracle website.
On Windows you may also need the Microsoft Visual C++ Redistributable (x64, x86, or ARM depending on your platform).
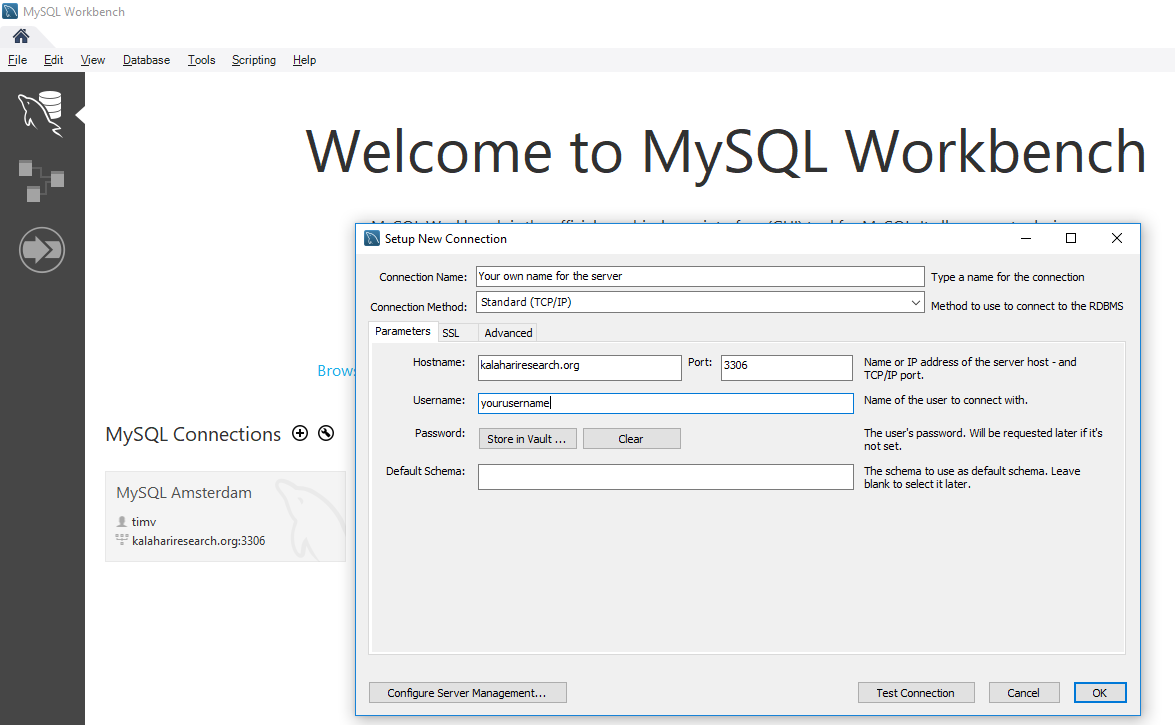
- Click the plus symbol next to MySQL Connections.
- Enter a name for your connection.
- Enter the hostname:
databases.kalahariresearch.org - Enter your username.
- Click Test Connection and enter your password when prompted.
- The connection will be saved and you can browse the schemas you have access to.
Before you write your first query: please read this
Filter on the server, not on your laptop.
The database is a shared resource. When you run
SELECT * FROM tblWeights, you ask the server to pull 1.7 million rows over the network, serialise them, push them to your machine, and then you typically throw 99% of them away in R or Python. This is slow for you, slow for everyone else connected, and a waste of bandwidth on the link to the field site.Learn the basics of SQL — at minimum,
SELECT,WHERE,JOIN,GROUP BY, andLIMIT— and let the database do the filtering. Your queries will run in seconds instead of minutes, and your colleagues will thank you.
Rule of thumb: every query should have either a WHERE clause, a LIMIT, or a tight JOIN that restricts the result. If you find yourself writing SELECT * FROM <big-table> without one of those, stop and rewrite.
Bad — pulls every weight measurement ever recorded, then filters in R:
weights <- dbGetQuery(krtdb, "SELECT * FROM tblWeights")
ak_weights <- weights[weights$Group == "AK" & weights$Date > "2024-01-01", ]
# 1.7 million rows downloaded, ~3000 kept. Network and memory wasted.Good — let the server do the filtering:
ak_weights <- dbGetQuery(
krtdb,
"SELECT WeightID, AnimalRef, Date, Mass
FROM tblWeights
WHERE GroupRef = ?
AND Date >= ?",
params = list(ak_group_ref, "2024-01-01")
)
# A few thousand rows over the wire, ready to use.The same principle applies in Python — see the Using Python section below. The WHERE goes in the SQL, never in a post-hoc filter on a giant DataFrame.
A short list of SQL clauses worth learning, in roughly the order you’ll need them:
SELECT col1, col2instead ofSELECT *— only ask for the columns you actually need.WHERE— filter rows before they leave the server.LIMIT 10— sanity-check a query before letting it run unbounded.JOIN— combine related tables in one query rather than pulling each separately.GROUP BY+ aggregate functions (COUNT,AVG,SUM) — summarise on the server.EXPLAINbefore your query — shows whether the server can use an index. If it says “full table scan” on a big table, you probably want a differentWHERE.
Good beginner resources: SQLBolt (interactive, ~1 hour), the MySQL SELECT reference, and your own database — ask for a read-only test account and just play.
Using R
The recommended package is RMariaDB, which works for both MySQL and MariaDB servers. Install it once, then load it in every script.
1. Install and load
install.packages("RMariaDB") # Run once, then comment out
library(RMariaDB)2. Store your password securely (recommended)
Never hard-code your password in a script that might end up in version control or get shared. Use the keyring package or your ~/.Renviron file instead:
# Option A: keyring (interactive prompt the first time, stored in OS keychain)
install.packages("keyring")
library(keyring)
key_set("krc_db", username = "yourusername") # prompts for password once
# Option B: edit ~/.Renviron and add a line:
# KRC_DB_PASSWORD=your_password_here
# Then read it with Sys.getenv("KRC_DB_PASSWORD")3. Open the connection
krtdb <- dbConnect(
MariaDB(),
host = "databases.kalahariresearch.org",
dbname = "Meerkatdatabase",
user = "yourusername",
password = key_get("krc_db", "yourusername") # or Sys.getenv("KRC_DB_PASSWORD")
)4. Explore the schema
dbListTables(krtdb) # All tables in the database
dbListFields(krtdb, "tblGroups") # Columns in a specific table5. Run a query and fetch results
Remember the warning above — your query needs a WHERE, a LIMIT, or a restrictive JOIN. For most read-only work, dbGetQuery() returns a data.frame in one call:
groups <- dbGetQuery(krtdb, "SELECT GroupRef, GroupName FROM tblGroups LIMIT 10")
head(groups)Always parameterise user input — never paste values into SQL strings (this prevents SQL-injection bugs and quoting headaches):
focal_group <- "AK"
result <- dbGetQuery(
krtdb,
"SELECT * FROM tblGroups WHERE GroupAbbrev = ?",
params = list(focal_group)
)6. Close the connection
dbDisconnect(krtdb)Alternative: RMySQL
RMySQL is the older sibling of RMariaDB. The two packages expose the same DBI interface, so the only line that changes is the driver. RMariaDB is the actively-maintained one and the recommended default, but you'll see RMySQL in older scripts and tutorials.
install.packages("RMySQL")
library(RMySQL)
krtdb <- dbConnect(
MySQL(), # <- only difference vs RMariaDB
host = "databases.kalahariresearch.org",
dbname = "Meerkatdatabase",
user = "yourusername",
password = key_get("krc_db", "yourusername")
)
# Everything from here on is identical: dbListTables(), dbGetQuery(),
# dbDisconnect(), parameterised queries with `params = list(...)`, etc.Which should you pick?
RMariaDB— recommended for new code. Maintained by Posit (formerly RStudio), works against both MySQL and MariaDB servers, supports modern auth plugins.RMySQL— fine for legacy projects, but no longer actively developed. Stick with it if you're maintaining an existing codebase.odbc— a third option if you already use ODBC drivers in your environment (e.g. you connect to several different database engines from one R session). Slightly more setup but database-agnostic.
Important: never load both RMariaDB and RMySQL in the same R session — they expose the same generic names (MySQL(), etc.) and whichever loads last will silently win. Pick one per script.
Using Python
The recommended driver is mysql-connector-python (Oracle's official MySQL client). For data analysis, pair it with pandas so query results land directly in a DataFrame.
Please re-read the "before you write your first query" section at the top of this page before you start. Pulling whole tables into pandas and then filtering is even more tempting in Python than it is in R, because the syntax is so terse — but the server load is identical. Filter with WHERE in your SQL, not with df[df.col == ...]
after the fact.
1. Install
pip install mysql-connector-python pandas keyring2. Store your password securely
Same principle as in R — keep credentials out of your scripts. Two common options:
# Option A: keyring (uses OS keychain — macOS Keychain, Windows Credential Manager, etc.)
import keyring
keyring.set_password("krc_db", "yourusername", "your_password") # run once, interactively
# Option B: environment variable
# Add to ~/.bashrc, ~/.zshrc, or set via your IDE's run config:
# export KRC_DB_PASSWORD=your_password_here
import os
password = os.environ["KRC_DB_PASSWORD"]3. Open the connection
import mysql.connector
import keyring
USERNAME = "yourusername"
conn = mysql.connector.connect(
host = "databases.kalahariresearch.org",
database = "Meerkatdatabase",
user = USERNAME,
password = keyring.get_password("krc_db", USERNAME),
charset = "utf8mb4",
)
cursor = conn.cursor(dictionary=True) # rows come back as dicts4. Explore the schema
cursor.execute("SHOW TABLES")
for row in cursor.fetchall():
print(row)
cursor.execute("SHOW COLUMNS FROM tblGroups")
for col in cursor.fetchall():
print(col["Field"], col["Type"])5. Run a query
For a one-off query (with the filtering done on the server, as discussed above):
cursor.execute(
"SELECT GroupRef, GroupName FROM tblGroups WHERE GroupAbbrev = %s",
("AK",)
)
for r in cursor.fetchall():
print(r)Always parameterise — pass values as a tuple, never with f-strings or string concatenation. Same reason as in R: prevents SQL-injection bugs and quoting headaches.
6. Read straight into a pandas DataFrame
For analysis work, skip the manual cursor and let pandas do the fetching:
import pandas as pd
df = pd.read_sql(
"""SELECT WeightID, AnimalRef, Date, Mass
FROM tblWeights
WHERE GroupRef = %(group_ref)s
AND Date >= %(min_date)s""",
conn,
params = {"group_ref": ak_group_ref, "min_date": "2024-01-01"},
)
print(df.head())
print(df.shape)7. Close the connection
cursor.close()
conn.close()Or use a context manager so connections always close, even on errors:
from contextlib import closing
with closing(mysql.connector.connect(
host="databases.kalahariresearch.org",
database="Meerkatdatabase",
user=USERNAME,
password=keyring.get_password("krc_db", USERNAME),
)) as conn:
df = pd.read_sql(
"SELECT * FROM tblGroups WHERE GroupAbbrev = %(g)s",
conn,
params={"g": "AK"},
)
print(df)Common gotchas
These are the four issues that bite almost every new user at some point. Recognising the error message is half the battle. Examples are in Python; R equivalents are at the bottom of this section.
"MySQL server has gone away" / "Lost connection during query"
The server closes idle connections after wait_timeout seconds (often 28,800 = 8 hours, but on shared servers it can be much shorter). If your script sleeps, waits for user input, or runs a slow computation between queries, the connection is dead by the time you try the next query. Network blips have the same effect.
conn = mysql.connector.connect(
host="databases.kalahariresearch.org",
database="Meerkatdatabase",
user=USERNAME,
password=keyring.get_password("krc_db", USERNAME),
connection_timeout=30, # seconds to wait for the initial TCP handshake
)
# Before any query in a long-running script, ping with auto-reconnect:
conn.ping(reconnect=True, attempts=3, delay=5)
cursor = conn.cursor(dictionary=True)
cursor.execute("SELECT 1")For very long jobs, prefer many short connections over one long-lived one — open the connection right before you need it, close it as soon as you're done.
Garbled accents and "?" characters (mojibake)
If observer names with accents come back as Andr?? or Bjö looks like Bj??, the connection charset doesn't match the table's storage charset. MySQL's "utf8" is the old 3-byte variant — for full Unicode (including emoji and many African languages' diacritics) you need utf8mb4.
conn = mysql.connector.connect(
host="databases.kalahariresearch.org",
database="Meerkatdatabase",
user=USERNAME,
password=keyring.get_password("krc_db", USERNAME),
charset="utf8mb4",
collation="utf8mb4_0900_ai_ci",
use_unicode=True,
)If you've already inserted garbled data, the connection charset can't fix it after the fact — the original bytes are gone. Always set the charset before your first INSERT.
"SSL connection required" or "Access denied (using password: YES)"
Many remote MySQL servers require TLS. The driver enables it by default, but if your user account is configured with REQUIRE SSL on the server side and your client isn't presenting a certificate, you'll be rejected with what looks like a wrong-password error.
# Minimum: ensure SSL is not disabled
conn = mysql.connector.connect(
host="databases.kalahariresearch.org",
database="Meerkatdatabase",
user=USERNAME,
password=keyring.get_password("krc_db", USERNAME),
ssl_disabled=False, # default; spelled out for clarity
)
# Stricter: verify the server's certificate against a CA bundle
conn = mysql.connector.connect(
host="databases.kalahariresearch.org",
database="Meerkatdatabase",
user=USERNAME,
password=keyring.get_password("krc_db", USERNAME),
ssl_ca="/etc/ssl/certs/ca-certificates.crt",
ssl_verify_cert=True,
ssl_verify_identity=True,
)If you genuinely need to connect over a trusted LAN without TLS (rare, and never over the public internet), pass ssl_disabled=True. Ask your DB admin before doing this.
Python eats all your RAM on a big SELECT
By default, mysql-connector-python uses a buffered cursor: it fetches every row into Python memory before returning control. A SELECT * FROM tblWeights over 1.7 million rows can easily exhaust a laptop — the same scenario the warning at the top of this page is about. The symptom is your Python process growing to several GB and
the OS killing it, or your machine swapping to disk.
The first fix is always: add a WHERE clause. If you genuinely need to stream a large result set (e.g. for a one-off export), use one of the patterns below.
Option 1 — unbuffered cursor (streams one row at a time):
cursor = conn.cursor(buffered=False)
cursor.execute("SELECT WaypointID, Latitude, Longitude FROM tblWaypoints")
for row in cursor: # streams from server, no full materialisation
process(row)
cursor.close()Option 2 — fetch in chunks with fetchmany():
cursor = conn.cursor(dictionary=True)
cursor.execute("SELECT WaypointID, Latitude, Longitude FROM tblWaypoints")
CHUNK = 10_000
while True:
rows = cursor.fetchmany(CHUNK)
if not rows:
break
process_batch(rows)Option 3 — let pandas chunk if you want DataFrames:
for df_chunk in pd.read_sql(
"SELECT WaypointID, Latitude, Longitude FROM tblWaypoints",
conn,
chunksize=50_000,
):
process(df_chunk)One trade-off: while an unbuffered cursor is open, you can't run another query on the same connection until you've consumed (or closed) it. If you need to query in parallel, open a second connection.
R equivalents
The same four issues show up in R with slightly different controls:
- Timeouts: pass
timeout = 30todbConnect(). For long jobs, wrap each query in atryCatch()and reconnect on failure. - Charset: pass
encoding = "utf8mb4"todbConnect(), or rundbExecute(krtdb, "SET NAMES utf8mb4")immediately after connecting. - SSL: pass
ssl.ca,ssl.cert,ssl.keytodbConnect(); or setclient.flag = CLIENT_SSL. - Streaming large results: use
dbSendQuery()+dbFetch(res, n = 10000)in a loop, thendbClearResult(res). Don't usedbGetQuery()for huge tables — it fetches everything at once. (And before doing any of this, ask yourself once more whether a tighterWHEREwould let you avoid streaming entirely.)